Three takeaways from comparing human and synthetic Gen–Z respondent data
Synthetic data is not a new concept or practice in market research. Long before the birth of online surveys, data scientists used well-established modeling techniques to fill-in data gaps by imputing missing values. Recently, the market research technology space began to proliferate with startups and incumbent tech companies alike, taking synthetic research to a new, more user-friendly level—prompting synthetic respondents to take online surveys in lieu of humans. With the step-change advancement in AI and large language models in particular, the synthetic respondent value proposition is enticing and its adoption in some capacity is likely inevitable.
Being in the business of customer insights, we wanted to see if Gen AI technology has reached the level at which researchers can confidently ask their questions of synthetic panels instead of humans.
Our short answer is ‘not yet,’ but that doesn’t mean there is no place for synthetic respondents in the researcher’s toolkit in the present. To illustrate our conclusion, we compare data we have received from two otherwise identical surveys – one completed by real human Gen-Z’s and one completed by a synthetic respondent panel, which we created to mimic profiles of those human Gen-Z’s. Here are our three key insights
Synthetic respondents answer simple multiple–choice questions reasonably well
In our experiment, we asked simple and multi-select choice questions. Some of the questions were directly related to the profiles of our synthetic respondent. For example, each synthetic respondent was prompted to answer our survey as a specific persona:
“I am a 19 year-old man who lives in Philadelphia, PA. I live with my parents. I think all the time about moving out to my own place. My timeframe of moving out to my own place is in the next couple of years. What prevents me from moving out earlier is: Money. My employment status is part time, and I like to shop at Weis”
The good news is that such persona would correctly answer a question about their age or gender. However, sometimes we unintentionally tricked them into providing a wrong answer. Some of our human respondents said that they lived with their parents AND rented their residence, implying that they paid rent to their parents. Synthetic respondents didn’t make that logical connection and assumed that such respondents lived with their parents.
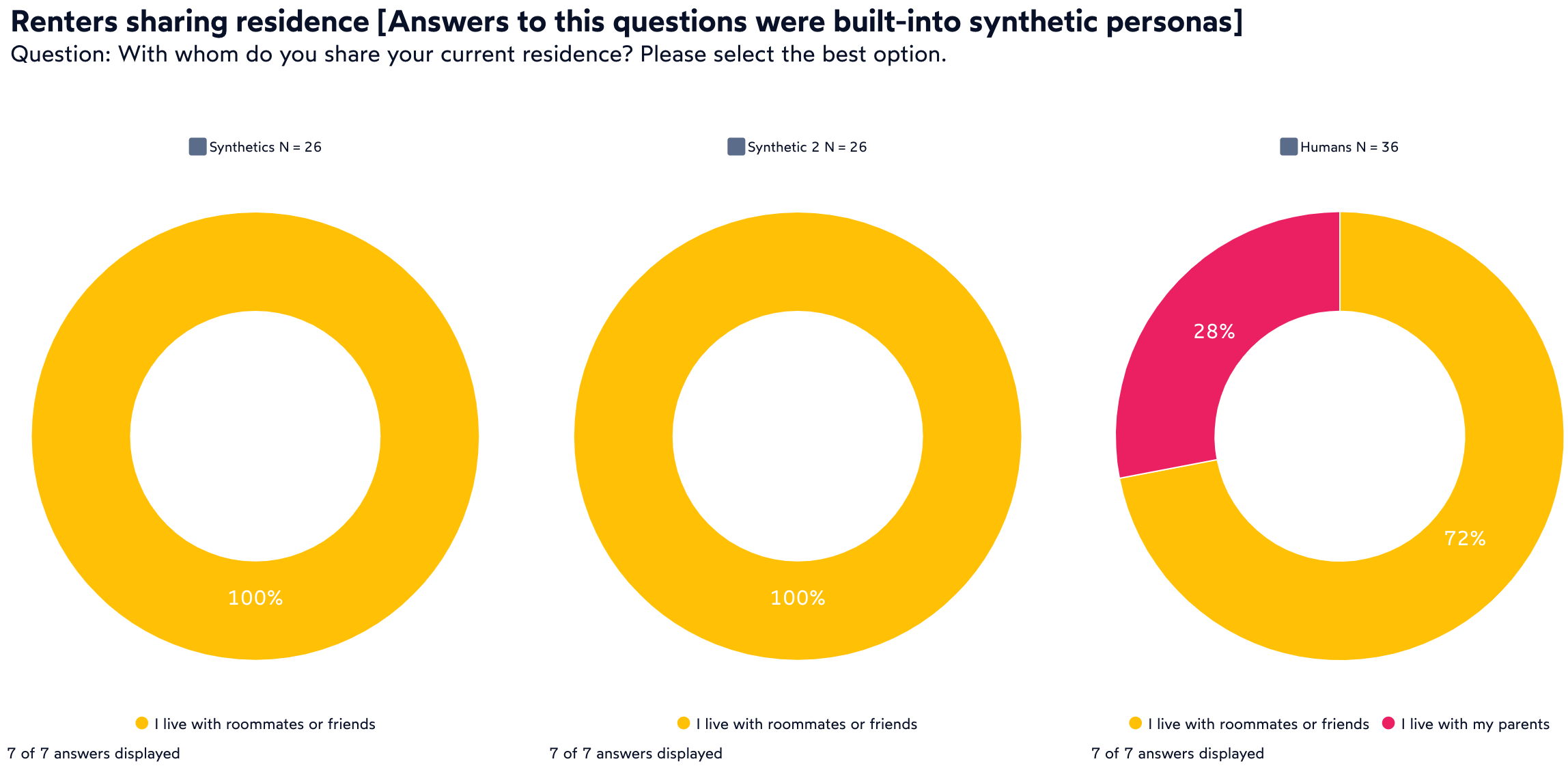
Where researchers need to be careful is asking questions – even simple multiple choice – where the synthetic respondent has not been well defined to be in a position to answer it. In other words, questions that veer away from how a synthetic respondent was defined into the unexplored, the answers can be far off from reality.
In our study example, most of our human respondents (and their synthetic avatars) still lived with their parents. During the survey we asked them who was responsible for making purchasing decision on common household items. In this case, more than half of our human Gen-Z’s told us that they share that responsibility. Their avatars assumed that it was the parents who made those decisions. Whether our human respondents fibbed a little bit and told us that they help their parents shop for those household items, it is hard to imagine that none of them are involved. A researcher relying on synthetic respondents to answer this simple question would receive a very skewed and inaccurate answer.
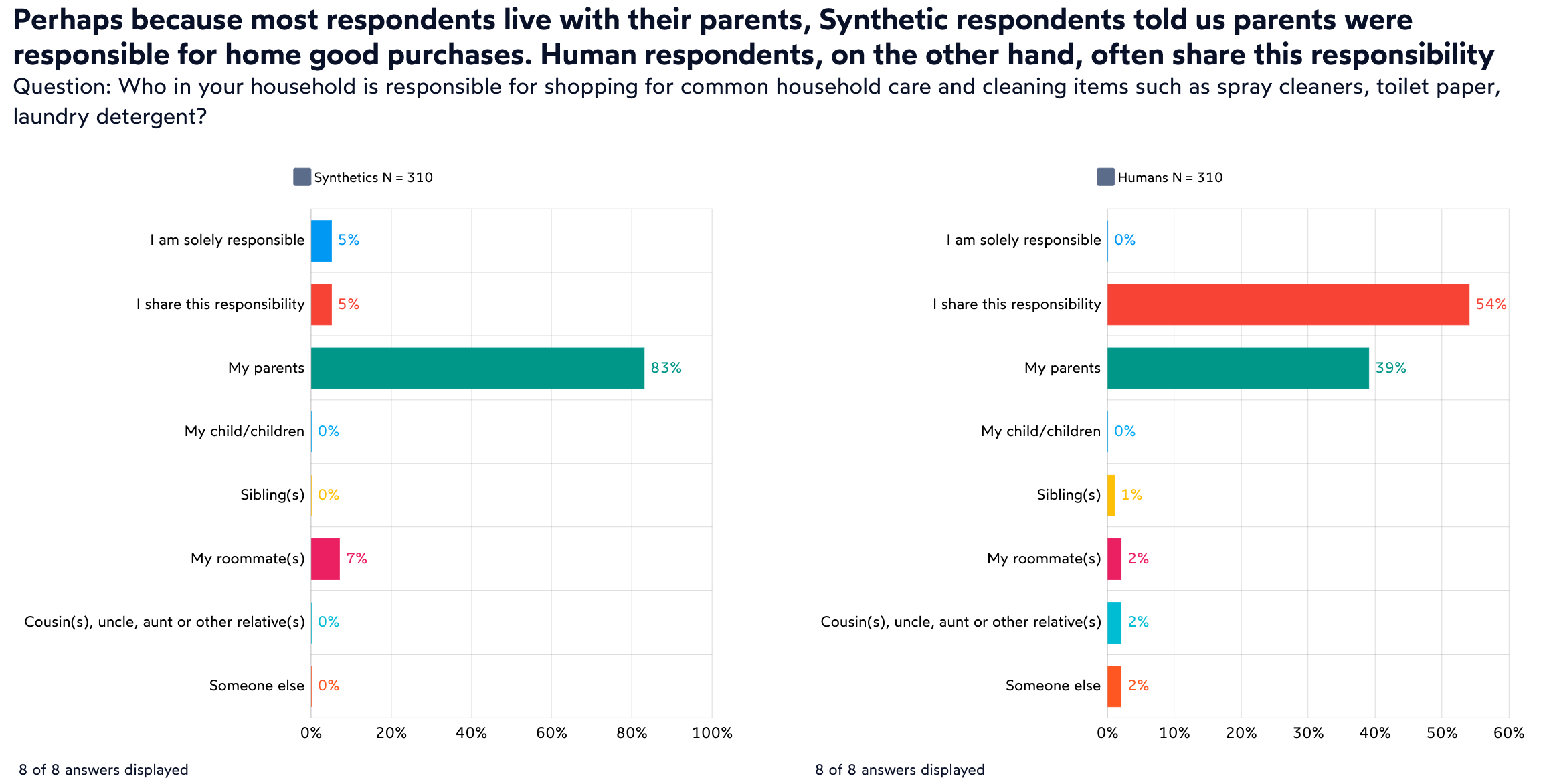
GenAI avatars struggle with open-ended questions
Synthetic respondents powered by Gen AI will provide answers to open-ended questions… and we should stop and marvel at this amazing achievement. That is the beauty of this technology, but this is also a source of potential danger to researchers. In our experiment, Gen AI respondents gave logical answers to open-ended questions, for example, telling us what would make them trust a home care product brand. The answers were logical and well-written. They also mirrored some of the answers humans provided. Where synthetic respondents fell short was in identifying a few less ‘obvious’ answers beyond reliability, efficiency and price. Humans talked about wanting brands to produce non-toxic products, products safe around pets, and having pleasant smell. Those areas were completely missed by AI.
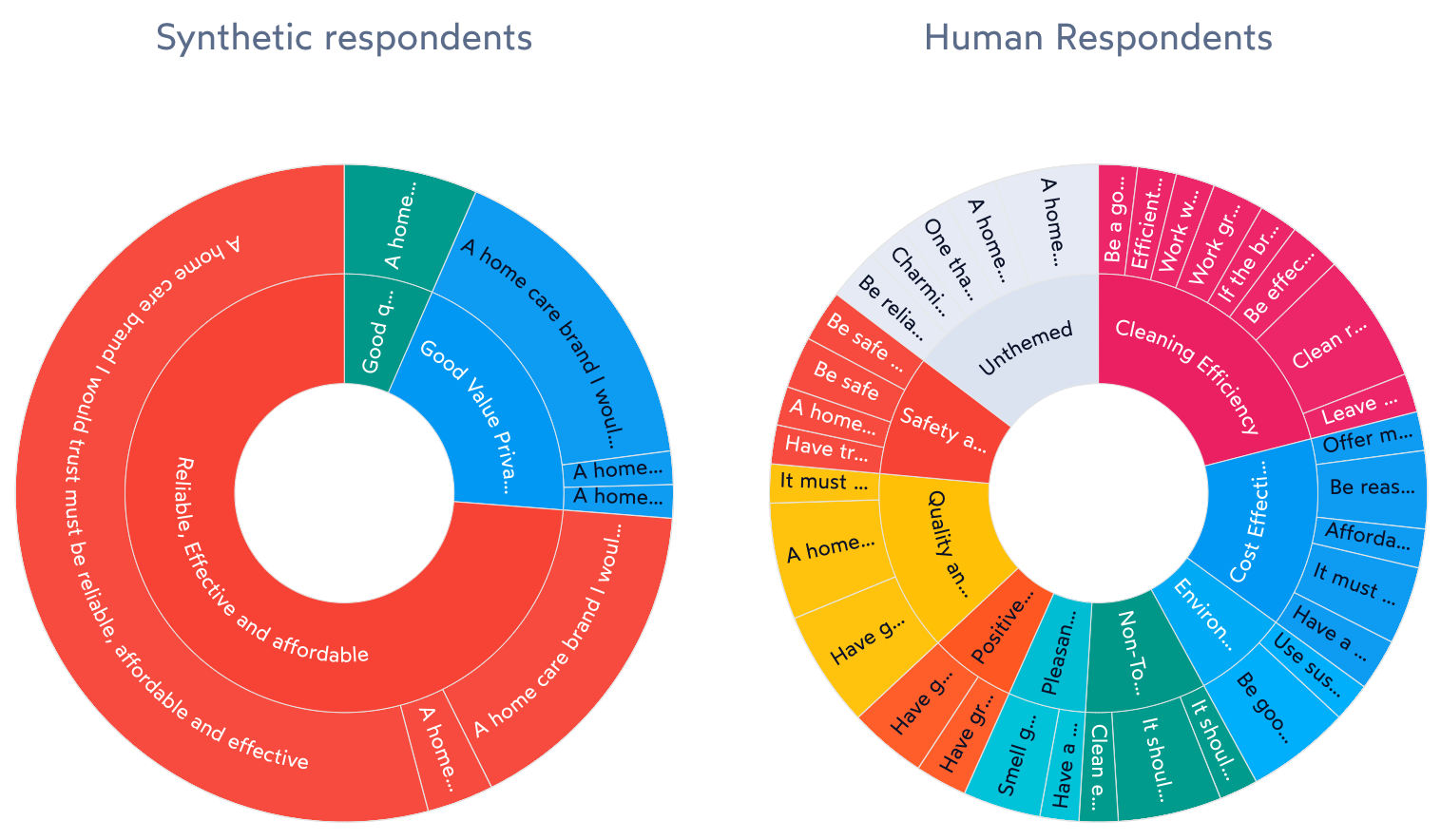
Synthetic answers lack breadth and nuance of humans
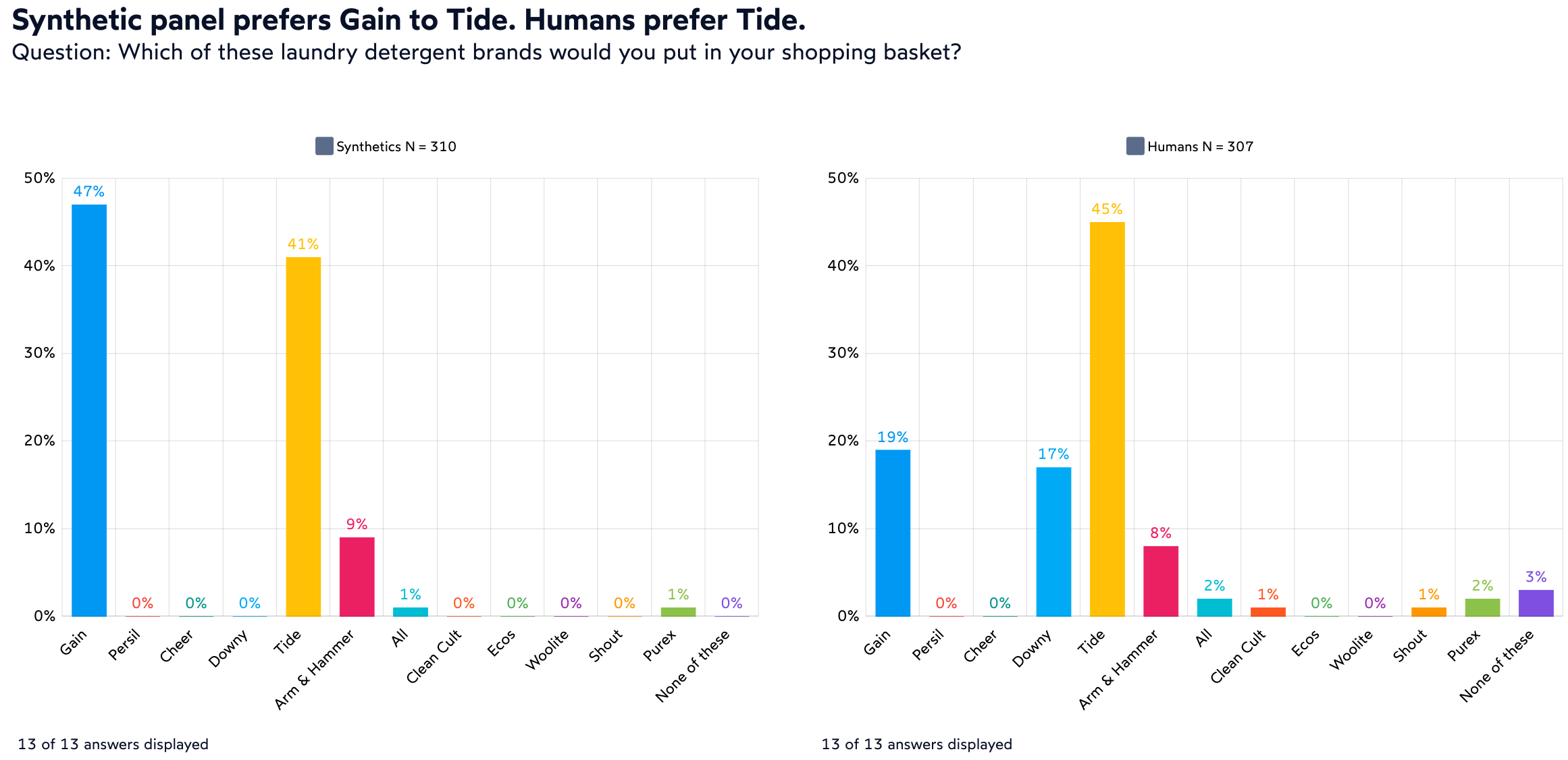
Perhaps the biggest difference we have found between human and synthetic respondents was in the breadth and nuance of response, both in choice questions and in open-ended responses. Take brand awareness for example. While synthetics in general identified correctly the most popular brands of product categories such as household cleaners or detergents, human respondent answers had more variance. Both humans and synthetics mostly preferred laundry detergents from Tide, Gain or Arm & Hammer. However, as you can see in the chart below, the distribution of answers between the two panels was significantly different.
The contrast in answer variance can be even more pronounced in open-ended questions. Going back to the question about “what makes you trust a home care product brand,” we note that synthetic respondents provided a total of 38 unique responses, but 80% of them were entered as only 6 unique variations. The most frequent answer was repeated 79 times, word by word: “A home care brand I would trust must be reliable, affordable, and effective.” Human responses, on the other hand, were much more unique: the most frequently repeated answer was “idk” (aka “I don’t know”) and it was only mentioned 9 times. The next most frequently repeated verbatim statement was “Be reliable” mentioned 3 times. In contrast to the 38 unique statements provided by 310 synthetic respondents, humans provided 291 unique answers, almost as many as the number of respondents.
Synthetic panels will get better, but they already offer practical applications
Having reviewed our experimental data, we can see two immediate uses for synthetic respondent technology. First, we conduct many very specific surveys with low incidence rates (IR). Those surveys are very difficult to test by humans or by randomly responding bots. Asking synthetic respondents who have been pre-defined with the correct qualifications makes survey testing a breeze in our experience. Not only can this approach test code for errors, it can also provide some idea of what the answers may look like and offer researchers a chance to refine question wording as needed before going in the field. Second, synthetic respondents can be used to mine existing data. Many of our clients conduct frequent surveys, and those collected data sets are a treasure trove of information… that is sometimes hard to comb through to recover insights. It may be easier to just run a new survey. However, converting existing data into synthetic respondents can constitute a quick and efficient data mining tool and avoid unnecessary new surveys and related costs and delays.
Weighing our experience with the synthetic respondent approach so far, we are both excited about its application but also offer a word of caution. To answer the question we asked in the beginning: yes, we believe that it takes humans to discover and validate new insights, particularly when it comes to product development, innovation and ideation. Humans can be long-winded, they are lazy with their grammar and sometimes make mistakes. But at the same time, they are thoughtful and nuanced and bring their personal experience into answering our questions. There is no doubt that Gen AI acting as synthetic respondents will make market research more efficient, but as long as companies innovate and build products for humans, they will want to rely on humans for feedback.



