When I started my first consulting job after business school, I distinctly remember the very first training I received: it was on the importance of asking open-ended questions and listening to what we hear back. That lesson has served me and my team very well at GroupSolver as we use the same approach when we ask our own customers what we can do for them, how we can do things better, and why they like working with us.
Unfortunately, while most of us intuitively understand the benefits of open-ended questions for customer insights, asking open-ended questions in traditional survey research has one central limitation: the text box. Typically, standard text boxes produce raw, unorganized data that are difficult to practically use without further cleaning and processing. Moreover, respondents often skip over them, making the researcher forgo any data from those respondents whatsoever. To illustrate some of the common challenges with the text box, we have reviewed data from a recent study where we deployed this traditional approach.
Text box approach leads to massive amounts of missing data
In this study, we evaluated perceptions of several ads within the US general population. Each respondent was asked to evaluate up to 5 ads, and during evaluation of each of them, they were asked to write down key messages they took away from watching the ad. To record their answers, for each ad, 5 text boxes were provided to respondents. Survey could leave the answer blank if they chose to. The same study was repeated over 3 weeks with the same ads.
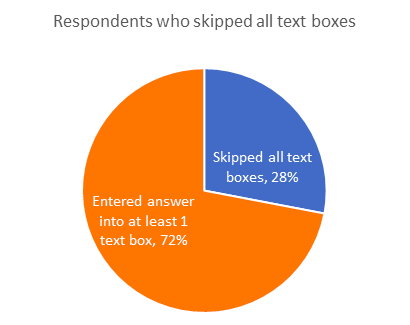
Out of 1698 panel respondents in this study, 28% did not write anything in any of the available text boxes. However, that does not mean that the remaining 72% provided answers to all questions they were asked: each of the 5 ads individually ended up with between 55% and 84% blank answers (64% on average). This means that many respondents provided their unaided feedback to some, but not to all of the ads they were asked to evaluate.
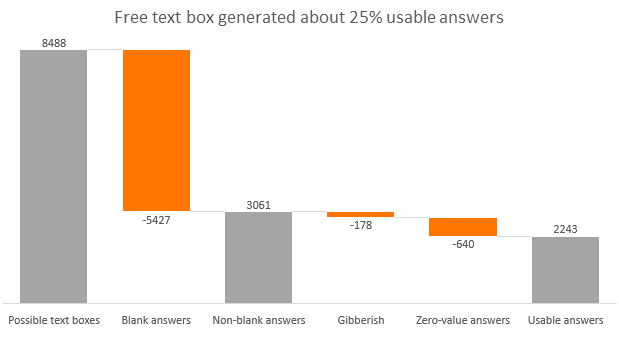
Going beyond the quantity of answers, quality also proved to be challenging. As anyone who has reviewed text answer data knows, not all text input is created equal. Sometimes, respondents simply type in random keystrokes or punt on a question by providing answers such as “I don’t know.” Such zero-value statements are not useful in an analysis. To understand how many recorded responses were useful, we ran our text cleaning algorithm on the data. This removed gibberish, profanity, and zero-value statements. Looking at the results, about 26% of text answers were either gibberish or provided no value. Out of 3,061 possibly valid free text answers, we only received 2,243 useful answers or approximately 73%. After accounting for all the blanks and useless answers, we ended up having just above 25% of possible answers ready to be analyzed.
One could make the argument that it is better for a respondent not to answer a question than to give a superficial or gibberish answer. However, by accepting this argument we also accept not receiving any feedback or input from a large portion of our respondents.
AI Open-End™ approach provides data from every respondent
There is, however, a way to approach open-ended questions that will not let a majority of respondents move past a question without providing us with some useful understanding of their thoughts. With a little help from machine learning and creative methodology, we can engage a respondent beyond filling in—or more likely not filling in – the text box. Taking this approach, a respondent is first asked to provide an unaided answer (just like in a traditional text box approach), however, after the unaided part is completed, our algorithm samples cleaned-up answers provided by earlier respondents and asks respondents the following question: “Others described the message using the following statement. Do you agree with it?” This step is repeated 5-10 times with each respondent, regardless of if they provided a free text unaided answer or not.
This approach accomplishes two things: First, we get data from all respondents. While not everyone may have provided a meaningful unaided answer into the text box (we call this phase “ideation”), at the minimum we get a read on how they feel about other answers that have proven to be important to the question at hand. Second, those important answers that are being evaluated in this phase (“evaluation phase”) get validated by a large number of respondents, which allows us to build confidence in the natural language answers received in the study. This allows us to build more robust “coded” answers than is possible with ex-post free text analytics tools.
Benefits of the AI Open-End ™ approach outweigh its costs
An AI Open-End™ approach may take a little more time for a respondent to complete as they are asked to evaluate 5-10 statements sampled by the system. This adds on average 15 to 45 seconds to survey completion time. However, respondents often report that they enjoy this process
more than a simple text box and they feel more engaged in the survey with this interactive approach. One of our customers described this approach as a more natural way to collect feedback: “It was like talking to a friend.”
While this investment of time by a respondent can make the survey longer, there are definitive benefits to the researcher conducting the study. A researcher no longer receives just a raw text file as an output of the analysis, but rather a cleaned, coded, and organized data set. Because the algorithm runs in real time along with the survey, summarized results are available as soon as respondents start providing their answers.
Furthermore, this qualitative data with an added dimension of statistical validation allows researchers to use it in more traditional quantitative analyses. Think about segmentation, pricing, or NPS studies where natural text data can be used as a categorical variable in a quantitative model.
Finally, AI Open-End™ methodology allows researchers to see which open-ended responses are significant and which matter less. This helps reduce analysis time and more importantly, it brings an objective measure to qualitative research outputs.
AI Open-End™ can effectively replace traditional table matrix questions
One way to overcome the limitations of a text box approach to open-ended questions while still probing for deeper insights, is to replace the open-ended “why” question with a multi-variable table matrix question. While this allows researchers to test multiple hypothesized answers to a single question without having to deal with unstructured natural language data, it comes at the expense of not hearing the true voice of the customer.
Moreover, we have seen in the literature (for example in this recent paper
) and in our own experiments
that table matrix questions may produce unreliable data and they are generally disliked by survey respondents. On the other hand, AI Open-End™ approach allows researchers to avoid limitations of the matrix question and lets survey participants freely ideate and validate their own hypotheses on the fly. Such unfiltered, organic voice of the customer is simultaneously validated, labeled and organized by the underlying algorithm to make data analysis as easy as that of a traditional matrix question.
The big picture: advancing from online surveys to organic conversations
Advances in computational technology and machine learning allow us to continue to move ever closer to meaningfully transitioning online research into a free-flowing natural conversation with the customer at scale while seamlessly combining open-ended and choice questions. To me, one sign indicating that we are getting closer to that goal would be observing fewer surveys with batteries of matrix questions and instead seeing more surveys simply asking consumer the “why, what, how” questions. At the end of the day, our job as market researchers is doing less talking and more listening to the consumers. Our surveys should be following the same approach.
Rastislav Ivanic, PhD, Co-Founder and CEO of GroupSolver



