One limiting factor in using survey data from open-ended questions is understanding the relationships between various free-text answers. When survey respondents provide their natural language responses by typing their answer into a text box, they are building a data set with unique, singular data points. Of course, such data can be then combined into themes or answer categories that improve our ability to understand the sentiment of the respondent group to some extent. However, even the best coders – human or machine-based – will not change the inherent limitation of one-dimensionality of free text data. A text-box approach to asking open-ended questions will always miss one critical aspect to such data, a multi-dimensionality that is readily available to data collected as multiple-choice questions calculated as correlations between any two answers.
Without understanding statistical relationships between answers provided by individual respondents, most data analyses would not be possible. Consider analyses that are the bread and butter of market research: building regression models, running correlation analyses, creating customer segments. All of these analyses depend on us understanding the relationship between variables and respondents. Such relationship can be represented by a correlation matrix between variables – a matrix that is impossible to build from free-text data. Fortunately, GroupSolver® has solved this problem and as the result, researchers now have for the first time the ability to understand the relationships between individual answers and thus craft a more intricate story from unstructured, language data.
IdeaCluster™ reduces N-dimensions of a correlation matrix to two
Question:
What one word describes how you are feeling today?_
 IdeaCluster™
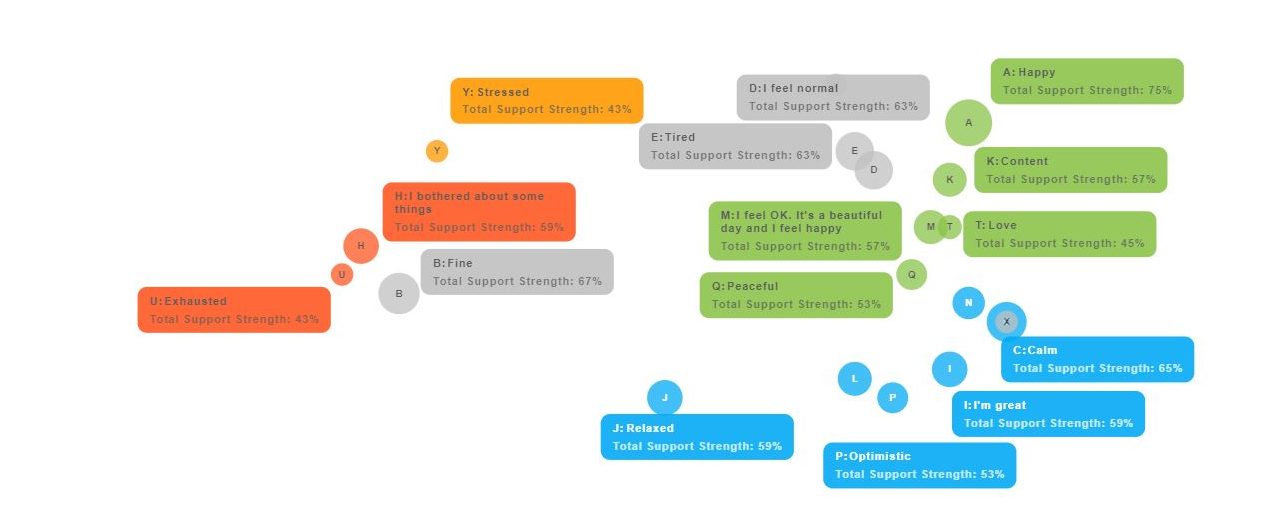
A picture tells a thousand words, so let’s take a look at a few examples from a recent study we have run on the topic of COVID-19 pulse checks
. One of the questions we asked our respondents was to tell us one word that describes their feeling. For context, this study was run online on October 7, 2020 in the middle of the Presidential elections in the United States, so the answer reflects the mood of the US population during this time. In this visualization you can see how the various answer themes (more traditionally called ‘codes’) naturally cluster together in different parts of the chart. The chart itself represents a reduction from n-dimensions to two using principal component analysis. Looking at this example, we see a nice continuum of answers from bottom right that express optimism and a relaxed feeling to a more emotional sense of happiness in the top-right. Each bubble represents one statement provided to us as a typed-in response to an open-ended question, and the color of the bubble represents a theme of that answer. Compared to the right side of the chart, the left side represents feelings, thoughts and emotions that are more negative. Interestingly, the answer “Fine” is clustered next to “Exhausted” and “I am bothered about some things” – perhaps our respondents are too exhausted and just resigned to just feeling “fine”–do we hear some sarcasm in that answer?
IdeaCluster™
A picture tells a thousand words, so let’s take a look at a few examples from a recent study we have run on the topic of COVID-19 pulse checks
. One of the questions we asked our respondents was to tell us one word that describes their feeling. For context, this study was run online on October 7, 2020 in the middle of the Presidential elections in the United States, so the answer reflects the mood of the US population during this time. In this visualization you can see how the various answer themes (more traditionally called ‘codes’) naturally cluster together in different parts of the chart. The chart itself represents a reduction from n-dimensions to two using principal component analysis. Looking at this example, we see a nice continuum of answers from bottom right that express optimism and a relaxed feeling to a more emotional sense of happiness in the top-right. Each bubble represents one statement provided to us as a typed-in response to an open-ended question, and the color of the bubble represents a theme of that answer. Compared to the right side of the chart, the left side represents feelings, thoughts and emotions that are more negative. Interestingly, the answer “Fine” is clustered next to “Exhausted” and “I am bothered about some things” – perhaps our respondents are too exhausted and just resigned to just feeling “fine”–do we hear some sarcasm in that answer?
In another question in the same study, we asked about sentiments towards the US economy. In this chart, the open-ended answers are again clustered along the spectrum from positive responses on the right to more negative assessment of the economic situation on the left. This left-negative and right-positive alignment in the two charts is purely coincidental, as statistically speaking, the axes of the chart do not have a specific meaning.
Question:
Thinking about the US economy, how would you describe your feelings about its performance?_
IdeaCluster™
In the chart it is easy to spot a continuum of answers, starting from bottom left going clock-wise, ranging from actively wishing for a change in political control in the Congress for the economy to improve (pink-red answers) through a more factual assessment of the economy not doing well and getting worse (orange and red answers) on the top left of the chart. The cluster of orange, red and pink-red answers represents the respondent answers with various degrees of unhappiness about the economy. On the right side of the chart, the blue and green answers are more positive. From top-right (blue) answers expressing optimism for future growth to green-coded answers saying that the economy is doing well. The light-green answers are interesting: they peg the success of the economy on current President’s ability to stay in power after the elections.
From manual coding of text answers to automation
The beauty of these simple examples is that they have been calculated automatically, in real time, and they didn’t require any manual coding or building a principal component analysis model. In the GroupSolver® platform, we automatically collect correlation data during the process of asking open-ended questions, which is then used to build the relationships between answers in real time using a built-in algorithm.
What this allows a researcher to do in real time is to focus more on understanding the story, the interesting pieces of information contained in these charts rather than on cleaning the data and coding it into usable form. In combination with other smart analysis available in our platform, the researcher can continue to peel the onion until the a-ha moment arrives.
For example, continuing to analyze the data set we have presented earlier, we can tell that women – and particularly Democratic-leaning women – tend to be feeling more anxious and tired. Males, particularly Republican-leaning men, feel more relaxed, hopeful and at peace.
Question:
What one word describes how you are feeling?_
IntelliSegment™
Understanding the relationship between answers given to us by respondents can uncover a much richer and deeper understanding of our customers. It gives us a more nuanced view of what respondents are telling us than a one-dimensional free text analysis. Going from a simple text analysis and coding of verbatim answers to quantified data sets allows us to understand the authentic customer responses in a much more rigorous and defensible way.



