Here at GroupSolver, we obsess over data quality. Not just because it’s our job—but because bad data can lead to bad decisions. And bad decisions? They can cost our clients millions.
We recently ran a concept test for a tech startup exploring a new product. The goal was to understand how their target audience perceived the concept, what resonated with them, and how much they’d be willing to pay. The project went very well and our client now has strong evidence to help them in their product journey. But what we discovered under the surface went far beyond collecting product feedback—it revealed just how damaging inattentive or fraudulent respondents can be if we didn’t pay attention to their threat.
The Hidden Cost of Bad Respondents
Let’s start with the basics. Bad respondents aren’t just a nuisance. They skew your sample, distort your insights, and can lead you to launch the wrong product at the wrong price to the wrong audience. In our study, we used Agatha, our data quality assurance system, to quality-terminate over 800 respondents, leaving us with 500 solid completes. Why so aggressive? Because the bad data wasn’t just noise—it was misleading our client to the wrong conclusions.
Demographic Distortion
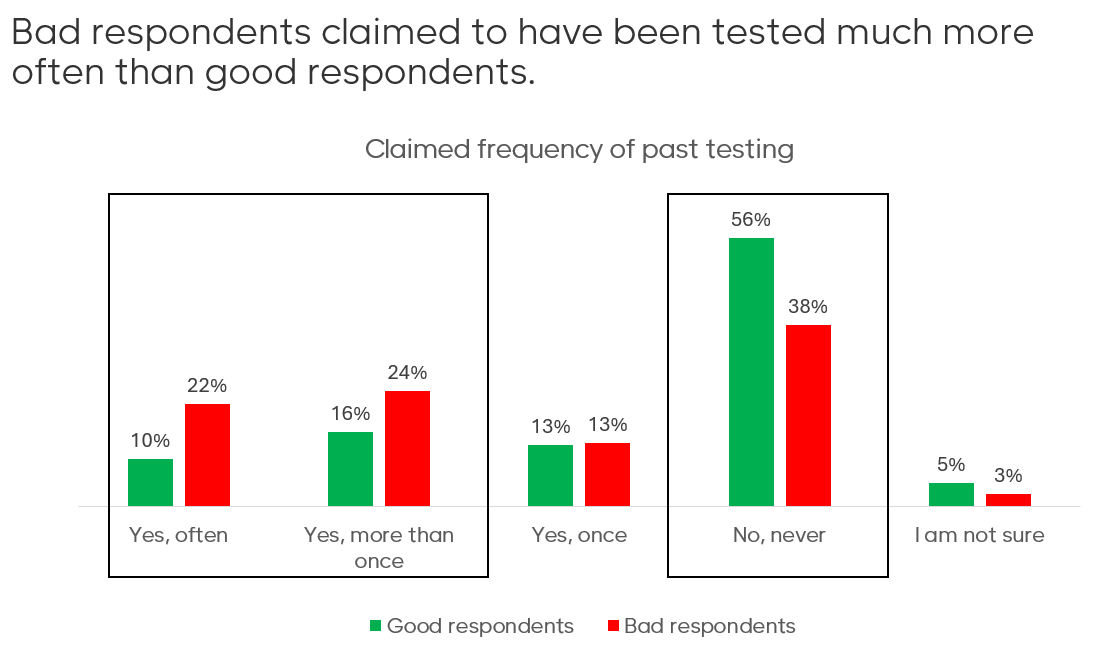
Fraudulent respondents often present themselves as younger, wealthier, and more male—traits that increase their chances of qualifying for surveys. But this demographic skew creates a false picture of your market. The product concept we tested was a replacement for a painful and expensive test. Honest respondents reported low frequency of testing—consistent with the product’s current barriers. Bad respondents, however, claimed they were getting tested far more often. That’s not just unlikely—it’s illogical and such exaggerated numbers would have led our client to believe that their market is larger than it actually is.
Misreading the Concept
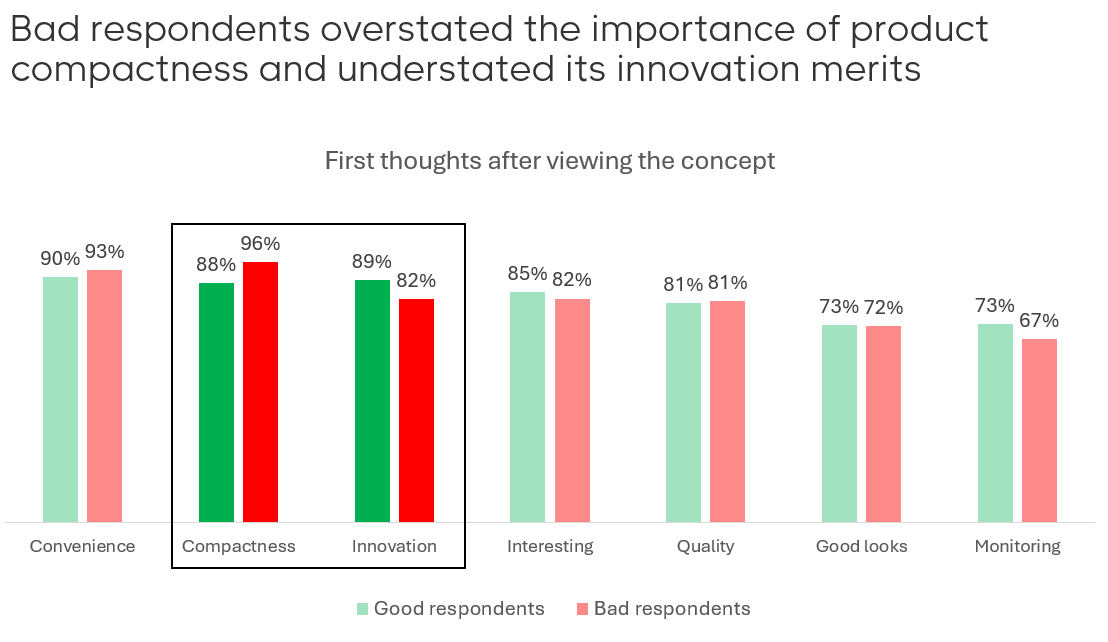
When asked for their first impressions, both good and bad respondents mentioned convenience and compactness. But here’s the twist: bad respondents over-indexed on compactness and under-indexed on innovation. For a product built on innovation, that’s a red flag. It suggests that bad respondents aren’t engaging with the concept meaningfully—they’re just clicking through. Moreover, a go-to-market campaign emphasizing compactness could miss the most resonating value proposition of the concept, which is its innovation.
Breaking the Laws of Economics
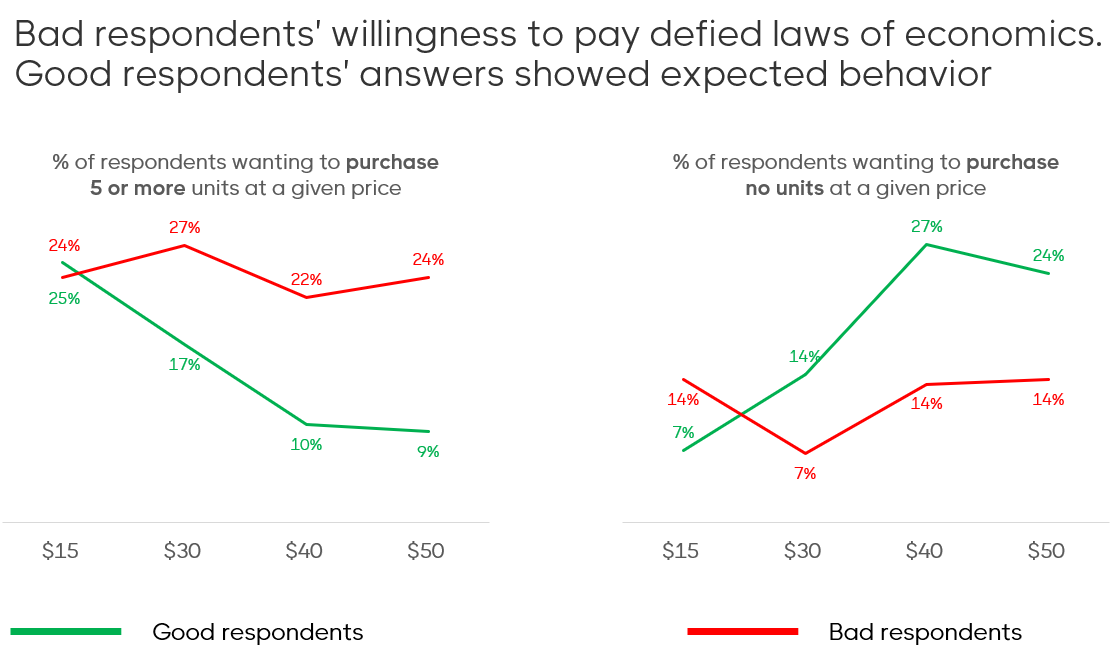
We asked respondents how many units they’d buy at four price points: $15, $30, $40, and $50. Good respondents behaved predictably: as price increased, demand dropped. Bad respondents? Their answers were erratic and price-insensitive. This kind of data can lead to dangerous pricing decisions. If you believe people will buy just as much at $50 as they would at $15, you might set a price too high and that may in turn kill your product demand before it even gets going.
In fact, that is exactly what would happen. To drive this point home, we conducted a classic pricing exercise and built a Van Westendorp model to give guidance to our client on what their future customers’ ideal price would be.
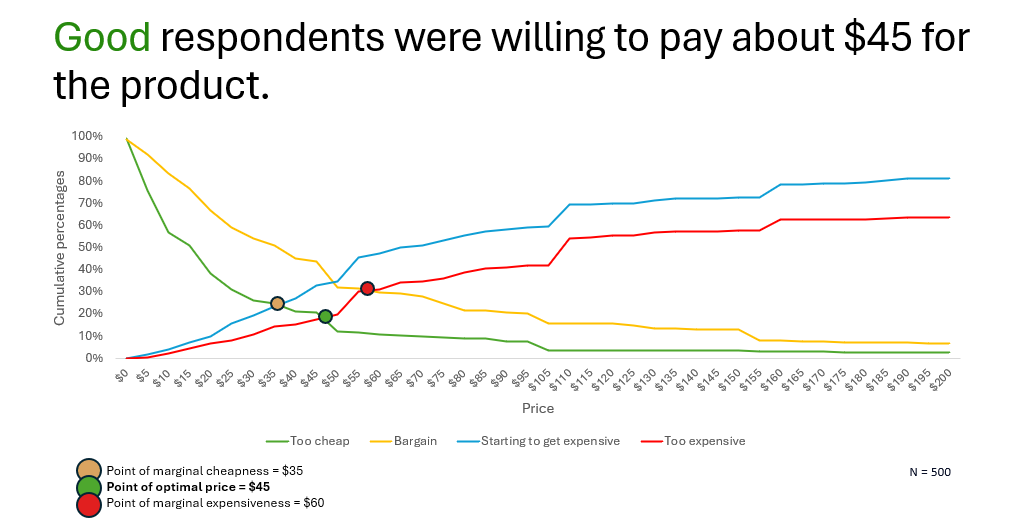
The respondents who have passed our strict quality checks indicated that they would be willing to pay between $35 and $60 for the product. On the other hand, those respondents we didn’t trust, indicated a much greater willingness to spend on the product.
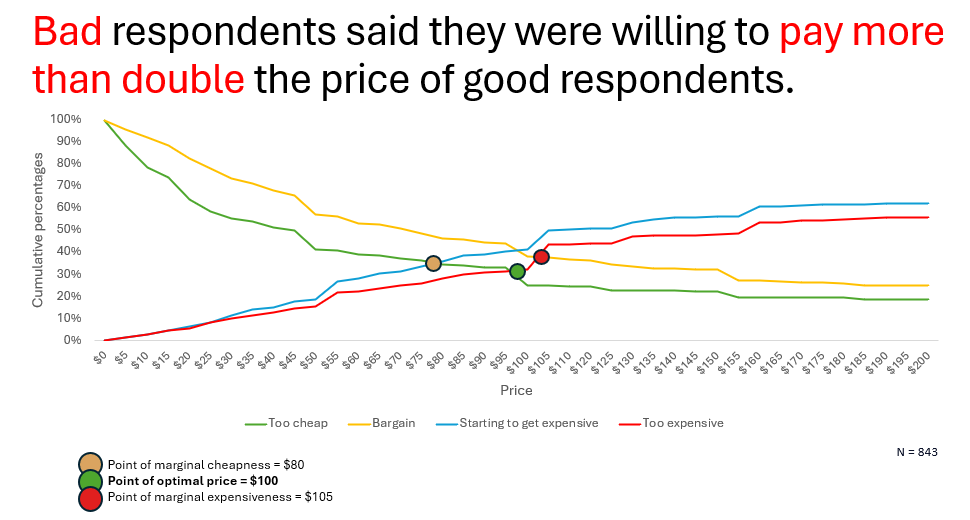
Note the difference in the shape of the curves, and how quickly “too cheap” and “bargain” lines drop toward 0% for real respondents. Bad respondents, on the other hand, really don’t have a clue what a bargain price might be, because they don’t really understand the product and what is its value proposition.
Not removing bad respondents could have led our client to making a potentially fatal mistake: setting their launch price too high while also expecting the market to be bigger than it really is.
What We Learned
This wasn’t just a lesson in survey design—it was another wake-up call and reaffirmation of our efforts to keep bad data out of our analyses. If there are three things to remember from this case study, it would be these:
Bad respondents distort everything—from demographics to pricing sensitivity.
They can’t be treated as harmless noise. Their impact is real and measurable.
Quality control isn’t optional. It’s essential to protect your insights and your bottom line.
In this case, removing bad data gave us a clear, actionable picture of the market. Without it, we might have recommended the wrong positioning, the wrong messaging, and the wrong launch price.
So yes, we stress about bad data. A lot. Because in market research, quality isn’t just a nice-to-have—it’s the difference between success and failure.



