Katherine Stolin[1]
, Charles Kennedy[2]
, Rastislav Ivanic, PhD[3]
Abstract
In our earlier paper on the topic of matrix questions, we explored findings from two parallel studies using alternative formatting of a matrix question. In that data, we found evidence that the traditional table format of a matrix question resulted in a small but statistically significant drift of mean scores toward the middle of the answer scale. To confirm this finding, we have conducted a follow-up study, again with two parallel online surveys but with a different set of questions compared to our first paper. Moreover, to explore some of the drivers of this phenomenon, we experimented with different lengths of the matrix question (10 rows vs 20 rows) and with different complexity of attributes evaluated by the respondents. We found that in the longer and more complex matrix questions, the drift was confirmed as hypothesized. Finally, to further validate our hypothesis that fatigue would drive midpoint drift, we put respondents through a filler task to replicate the fatigue a respondent would feel in the middle of a live study.
Data
** **
**and **
methodology
In this study, we conducted two identical surveys on two different platforms. After first performing a filler task for approximately ten minutes, respondents answered two matrix questions on the topic of frozen food.
Each respondent was randomly assigned to one of the two platforms after initially starting the survey on Platform A, where they performed the filler task. Of the 639 total respondents, 312 continued the exercise on Platform A, where the matrix was presented as individual questions one-by-one. Meanwhile, 327 respondents were redirected to Platform B, where the matrix question was presented in the traditional table form. In both cases, the total length of interview (LOI) was about 15 minutes, which included a filler task in the beginning of the survey before the assignment to Platform A or Platform B.
Once assigned to one of the platforms, respondents were asked 2 matrix questions in a random order. The first matrix question was about brand awareness, where respondents were asked to rank their preference for a set of frozen food brands. This question represented a type of matrix with simple attributes, which are quick to read and easy to comprehend. Each respondent was asked this question in one of the 4 different forms: the question had either 10 or 20 rows of attributes with a corresponding number of brands to evaluate as well as using either a normal or reverse 5-point scales to measure the effect of option placement on the screen.
The second question represented a matrix with more complex attributes using more elaborate language, making the attributes longer for someone to read and comprehend. Respondents were asked to rate attributes of their purchase decision for frozen food. Each attribute was a sentence ranging between 6 and 23 words. As with the question about brands, a respondent was randomly assigned a question with either 10 or 20 rows and a normal or reverse scale.
The total number of respondents in each cell of this experiment is summarized in Table 1 below.
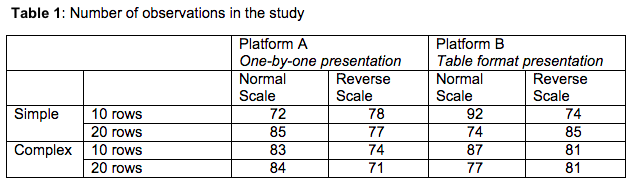
In our analysis, we combined the data using observations from answers with normal and reverse scales.
**Simple attribute matrix **
When comparing the results for the 1st experiment – using simple attributes as rows in a matrix question – we did not see a statistically significant difference in the resulting means between the two methods.
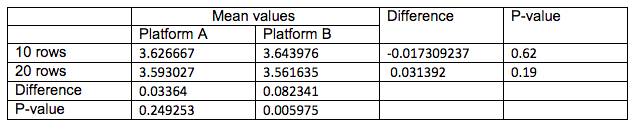
While there appears to be no statistical difference in the results between the two platforms, we observe that within each separate platform, longer matrices do seem to result in average scores that are closer to the mid-point of the scales, which in our 5-point scale was a value of 3.00. This result is statistically significant on Platform B, which presents matrix questions as a traditional table. One explanation for this phenomenon could be that longer matrices lead to greater fatigue or annoyance for the respondent, which may increase the likelihood of marking a middle answer. When a long table is displayed at once, it is clear to the respondent that the task at hand is long, and that may lead to giving up on reading the options thoroughly. This makes a respondent more inclined to provide a neutral answer when evaluating poorly understood attributes.
**Complex **
**attribute **
**matrix **
From the simple matrix example, it is not clear if there is any measurable difference in drift toward the middle between the two methods. However, our hypothesis was that the drift would be more pronounced in more tedious exercises. Therefore, we conducted a 2nd experiment where we amplified the amount of effort needed to read and comprehend the answers, which translated into longer amounts of time spent on each matrix. Comparing the results of this experiment, we observe statistical differences between the mean values obtained from the two platforms.

These appear to confirm our hypothesis that – relative to showing matrix attributes one-by-one – a traditional matrix table does result in mean values closer to the middle point of the scale. In addition, using the more complex matrix seemed to amplify the drift towards the middle for longer matrices. Within both platforms, the mean values are closer to the midpoint (3.00) in the 20-row matrix. Unlike the simple exercise, this trend was statistically significant on both Platform A as well as Platform B.
Discussion
** **
We conducted this follow-up study to test whether the observed drift of mean values in a matrix question toward the middle could be replicated in a different set of questions, while controlling for the direction of scales, complexity of matrix attributes, and length of the matrix question. Based on this data, it appears that the table format of the matrix question has some impact in questions that are more involved for the respondent to process. While evidence comparing the two methods using simple matrix questions was inconclusive, comparing data obtained form more complex questions confirmed our hypothesis.
This study provides additional evidence in support of the notion that asking matrix questions in online surveys using traditional table format could lead to less differentiated data. While our research did not focus on isolating specific drivers that contribute to causing the drift in matrix questions, future research could help researchers build a better understanding of this topic. Such understanding would be extremely valuable to market researchers designing online surveys as it could positively impact survey design best practices and thus help deliver higher quality of data.
[1] GroupSolver, San Diego, CA, USA
[2] GroupSolver, San Diego, CA, USA
[3] Corresponding author; ivanic@groupsolver.com
, GroupSolver, San Diego, CA, USA